Suggested Reading
Article
Editor's Picks
THE PEOPLE ARE IN THE COMPUTER—PART I
Peter Bauman
•
November 4, 2025
View




In this written form of the conversation, deep learning engineer and generative adversarial network (GAN) inventor Ian Goodfellow speaks with Peter Bauman (Monk Antony) in depth about the legendary origins of GANs, their unexpected success and indelible impact on both twenty-first-century image making and AI research. The full audio form of the conversation is now available on podcast and YouTube.
Peter Bauman: GANs have played an outsized, enormously significant role in the development of deep generative models, especially in the transition from tasks like feature learning to actual synthesis and generation.
In your own words, can you explain what GANs are and what they do?
Ian Goodfellow: That turn to focusing on synthesis and generation of media is also something really crucial to touch on.
To start explaining what GANs are: GANs are a solution to the generative modeling problem. The generative modeling problem is, broadly speaking, you have a data set containing a lot of examples of something. For GANs, that's usually photographs. Maybe you have a lot of photos of faces. Those faces all come from some probability distribution.
We want a learning algorithm to learn the probability distribution of realistic faces and then generate more faces like them. GANs do that by having two different neural networks compete in a game, in the formal game-theoretic sense.
One of those neural networks is a generator network. You can think of that one like an artist. And the other network is the discriminator network that you can think of like an art critic.
Except it's not really a stylistic art critic but more looking purely at realism. In the game, the generator produces an image of, for example, a face. Then the art critic looks at either real images or fake images coming from the generator. For each individual image that the art critic sees, they have to estimate a probability of whether the image is real or fake.
The generator gets a learning signal based on the probability coming from the art critic. So the generator tries to drive the art critic's probability up toward one. The art critic tries to drive their probability on fake samples down to zero and their probability on real samples up toward one.
We can actually analyze this with game theory and show what the Nash equilibrium is, the point at which neither player can improve their strategy. For the artist, that’s learning to produce perfectly realistic images of faces. For the art critic, it’s having to essentially do a coin toss on every image because they’ll all be perfectly realistic.
Back in 2014, that sure seemed theoretical to most people. I think in 2025, we're now seeing that AI fakes can be good enough that it's really hard to tell.
.jpeg)
Peter Bauman: Speaking of 2014, the GAN origin story is now legendary, starting with a grad student send-off night out in Montreal on May 26th, 2014, which was only a few days before the NIPS 2014 deadline you were not planning on participating in.
Ian Goodfellow: That date sounds correct to me. It was about two weeks before the deadline for NIPS. I had not been planning to write a paper for it that year; I was working on writing the Deep Learning textbook instead.
One thing that's important to understand in terms of the speed that everything happened is everyone involved in this story had been working on neural nets and ideas related to generative modeling for years beforehand. We weren't trying to solve the generative modeling problem per se but a lot of us had thought that using generative modeling as a practice exercise might help neural nets to solve supervised learning. That’s when you show the neural net a face and you ask it, for example, “Is this person smiling, frowning, and so on?”
By 2014, it had turned out that you could solve the supervised learning problem without having to do a warm-up using generative modeling. But all of us had a lot of practice doing generative modeling for several years beforehand.
We all had ideas floating around in our heads that clicked in place on this night. It's not that they came out of nowhere.
I'd actually been working from my girlfriend's house, writing the textbook, as I had already handed in my thesis. I was basically done with grad school so my lab mates hadn't even really seen me very much for a little while. This party was a going-away party, both for me and for my colleague, Razvan Pascanu, who was going off to DeepMind.
Since it was their first time seeing me in a while, some of my fellow students were asking me for programming advice. These nights at the bar often ended up with friendly academic debate and sometimes friendly software engineering strategy debate.
In this case, we ended up in a pretty big disagreement about how to solve the problem that they were asking me for help with.
They were saying that they wanted to make a generative model that had essentially a generator that would spit out photos. Then they wanted to check if the average brightness of all the pixels in a batch was correct. Then they wanted to check if the correlation between all the pairs of pixels in the batch was correct. And then they wanted to check if the product of all three pixels for all triplets of pixels in the batch was correct.
Just checking pairwise correlation won't get you very far in terms of producing a realistic photo. But they thought maybe if we bring in triplets of pixels, we can start to get interesting structure in the image. The problem is there are a whole lot of triplets. If you have a thousand pixels, which isn't even very many pixels in an image, you're already talking, like, a million triplets.
They were asking my advice for how we could write a program that was able to process so many triplets. I was walking them through the math of, “Well, here's how many pixels are in your image. You're going to process not just one image, but a batch. Here's how much memory is on the GPU. You're not going to be able to program your way out of this. There are just too many triplets.”

So I suggested, “How about instead of trying to make a big, long list of all the triplet features, you have a neural net learn the features that you should look at? And have a list of, like, a thousand features that you think describe what you're looking for in the photo.”
That was essentially the embedding space of the discriminator network that I was describing.
Have a discriminator network keep looking at the photos and the last hidden layer of the discriminator network gives you a set of a thousand features that you can track instead of billions or trillions of triplet features.
Their response was basically, “It's hard enough to train one neural network; you can't train a second neural network in the inner loop of training the outer neural net,” which is a fair objection.
That's a lot of why GANs are not the state of the art in generative modeling today. This GAN idea worked well enough that it got the ball rolling on image generation, but it did eventually get superseded by ideas that didn't involve this layer of complexity. At the time, we didn't know of a great alternative yet.
The context of being at the going-away party and having just a little bit to drink was important. I think a lot of the time having your inhibitions lower just a little bit is useful for trying out an idea that you wouldn't try if you were in the lab analyzing things really coldly. There are a lot of ideas that you might shoot down just a little bit too early.
So my fellow students really didn't want to try it out. I did want to try it out.
And I actually had quite a lot of code lying around from a previous paper that made it pretty easy to glue together.
We had a previous paper on just the supervised part, where I could take the supervised model and use that as the art critic part, the discriminator. Then I could essentially copy-paste that and turn it upside down and make that the generator.
Then the only new piece of code I really had to write was a little bit to say, "Flip the learning signal around and follow it backwards," and that becomes a learning signal for the generator.
When people hear that I wrote this really, really fast, it's not that I wrote it from scratch. It's that I had a really good code base already set up with all of the instrumentation and tooling to make it easy to make changes really fast.
The other thing that was important was I got incredibly lucky that the first time I ran it, it worked.
There are lots of different settings you have to set on a neural net. When you update the weights, how big should the update be? How big should each layer be? How many layers? Dozens of things like this.
Many times you have to launch a job at a computer cluster and search through dozens of different combinations of settings before you get anything reasonable. I was really lucky that just taking the best settings from supervised learning from an earlier paper and copy-pasting everything, even though I was taking it and flipping the generator upside down, just worked on the first try.
The first thing that I trained was taking little images of handwritten digits from a data set called MNIST that's really overused in machine learning research but it's also very fast to train on. And the very first time that I trained on it, it worked.
For anybody that was used to the previous generation of deep learning generative models, Boltzmann Machines, just the ease with which that happened made it really obvious that this was something different.
With Boltzmann Machines, you spend quite a lot of time struggling to get them to produce recognizable MNIST digits. This just went ahead and spat out MNIST digits in two minutes. From that, I was excited and e-mailed the lab more or less right away.

Peter Bauman: Were those initial MNIST digits, which were the very first GAN images, the ones that you used in the paper, or are they lying around somewhere?
Ian Goodfellow: They’re not the ones used in the paper. And I do have them. They're just in my Gmail outbox. I could forward them to you.
Peter Bauman: Sure, that would be really interesting to see. That’s quite special, the first GANs ever created the very first night. And how late was this mythical night?
Ian Goodfellow: My girlfriend hadn't come to the going-away party and she was asleep. I think she had work the next day and I was only writing the Deep Learning Book so setting my own hours.
I only stayed up an hour after coming home because it was very fast to get it working.
Later, I did end up pulling an all-nighter while writing the NIPS paper. There the funny story is my girlfriend was saying, “Are you working too hard? Is this good work-life balance?” Not saying I shouldn't, just checking in and evaluating: are we making good choices here?
And I was saying, “Yeah, it's definitely worth it to pull an all-nighter for this. This is going to be bigger than Maxout.” Now everybody that hears that story is like, “What's Maxout?”
It was a paper I wrote that was the most cited paper of ICML 2013, which we thought was a huge deal until GANs. Then clearly, GANs were the much bigger deal.
Peter Bauman: So you make the first GANs with those MNIST digits and email them. Then what happened next?
Ian Goodfellow: The very first night I got the MNIST samples; the next day I sent them to the lab. I hadn't been going to the lab in person and was telling everyone, “I'm not doing research anymore. I'm writing a deep learning book.”
But I've got this idea. Who wants to write a NIPS paper with me? And a bunch of people in the lab were like, “You have my sword.” “You have my bow.” And we all worked really hard for two weeks and shipped the paper.
Peter Bauman: So the paper itself in those two weeks was quite collaborative?
Ian Goodfellow: Yeah, once I realized I was writing a paper, I was back to going into the lab, back in grad student mode. The paper was really very collaborative. For the NeurIPS Test of Time Award talk in 2024, my co-author, David Warde-Farley, did the talk. We really emphasized that it takes a village to do this thing. All of the co-authors each made important contributions, but beyond that, the lab itself was the environment that it took to be able to do this.
People like Frédéric Bastien, who was a lab employee, developed and maintained tools like Theano, the software library that we used for all of our research. He actually had been working on a feature for Theano that we realized we needed to be able to finish the paper. And he rushed and finished it in time for us to be able to write the paper. So this was a massive collaborative effort involving people on the paper and even people not on the paper who are rather credited on the Theano publications.
Peter Bauman: Then from what I understand, that paper kicked off an intense competition to make GANs more usable. They were even part of Fei-Fei Li and Andrej Karpathy’s Stanford course on neural nets for visual recognition, which began in January 2015.
How quickly after you presented it did you get the sense that this would be of interest to even those outside the ML community?
Ian Goodfellow: There was noticeable interest right away but it wasn't the intensity that came later. A lot of things in machine learning get out of date really fast. Often, things are more like Maxout, where it's the most cited paper of ICML 2013 but then people move on to something like ResNets pretty soon.
There's a pretty short lifespan of something being state of the art. What was a bit more surprising about GANs is that they stayed really popular for at least five years.
Even now, they haven't totally died. There's still adversarial training as a component of a lot of image generation systems.
So the longevity was more surprising than the popularity, if that makes sense.
Pretty early on, I could tell, yeah, this will definitely be the flavor of the year. I didn't realize that it would last longer than that. When I realized that it had pretty big traction was LAPGAN, where they scale up the image to several different resolutions, by Remi Denton and Soumith Chintala, which actually was a bit slow.
That was when there was really high-quality, high-investment work following up on it and that actually took about a year after the first GAN paper.
Peter Bauman: The major players working with GANs right away in those early days were the Stanford class, Remi and Soumith at Facebook, and then Alec Radford, also early in 2015, doing essentially independent research.
Ian Goodfellow: Yes, DCGAN became public November 2015.
That was the corner of the hockey stick; that was when it did really take off. With LAPGAN, I was like, “Yeah, this is definitely going to go somewhere.” Then DCGAN was like, “Okay, it actually is going somewhere.”
Peter Bauman: Yeah, it’s remarkable how that hours and days after Alec posted the DCGAN paper, how many different artists started picking up on it and how much cultural attention it got.
I’d also like to hear from you about the importance of deep generative modeling more broadly and long-term. There's a diagram in your Deep Learning textbook that essentially presents deep generative modeling as the culmination of deep learning. Is that accurate?
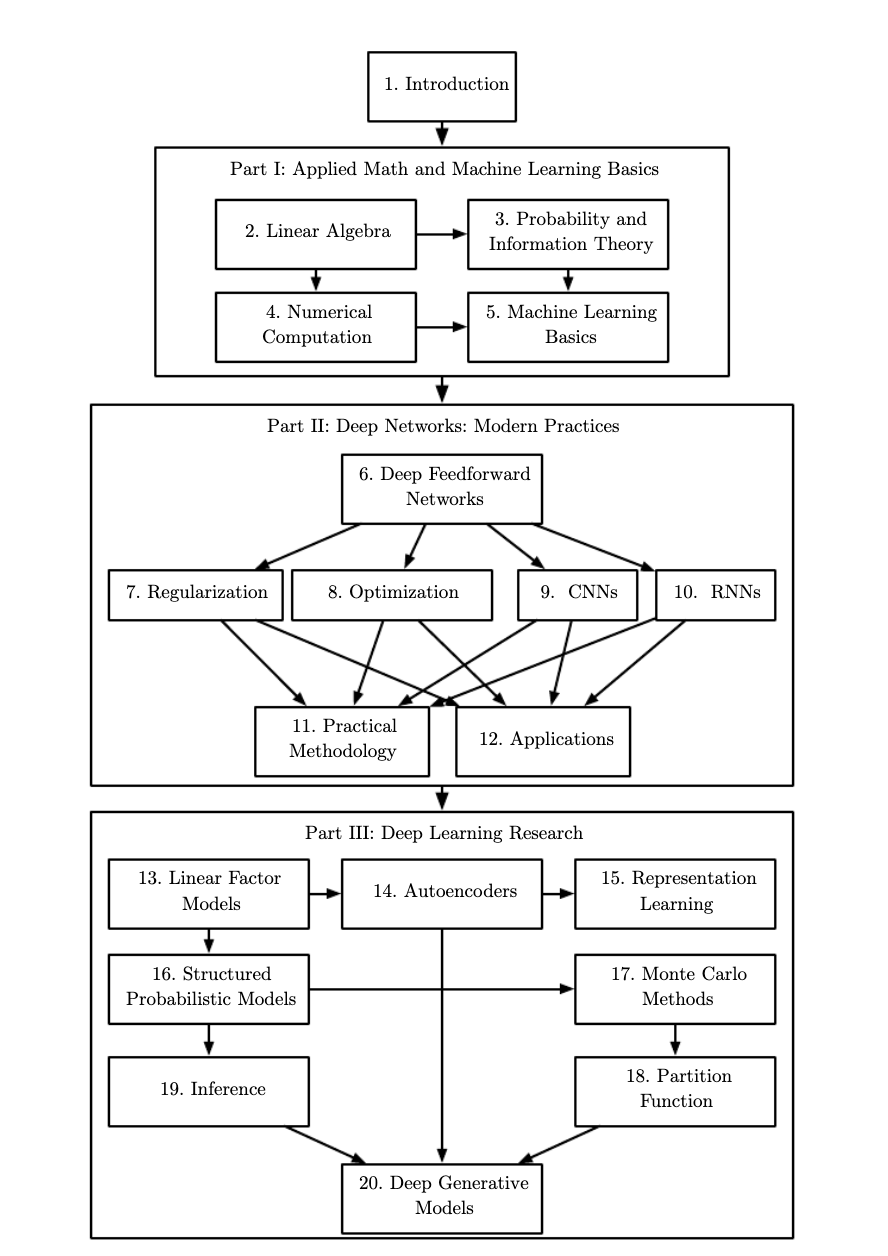
Ian Goodfellow: That's the way the industry has gone but that's not what we intended with the book. In the book’s intro, we actually say there are important topics we aren't covering, like reinforcement learning.
At the time that the book came out in 2016, a lot of people viewed deep reinforcement learning as the culmination and questioned the fact that we weren't covering how AlphaGo worked in detail; many viewed AlphaGo as the culmination of AI at the time. But none of us three authors had enough RL expertise to write a good chapter on it, which was viewed as a defect of the book.
The order of the book is more based on two principles. One is if people start reading front to back, we want them to go in the order of prerequisites. So we start with all the math fundamentals that they need to be able to understand later on. So partly generative models are at the end because they have the most prerequisites.
The other thing is we tried to order it from least to most likely to get outdated. At the start of the book, there's linear algebra, which is not going anywhere. Then at the end of the book, we're like, “Here's PixelCNN: it's probably going to be out of date by the time we print it.” We're moving from general to specific so by the time you're talking about deep generative models, you have to be pretty specific.
So no, I don't think generative models are necessarily the culmination of deep learning. There are a lot of other interesting things you can build on top of deep learning.
The way the industry has gone, it's been a little bit surprising that almost everything powerful we have built has had a generative model in it for several years.
But when we wrote the book, it felt more like we're all generative model experts, and we're biasing it toward what we know.
It turned out we knew something pretty powerful.
Peter Bauman: I’m also interested in what GAN technologies actually are in the words of their inventor. One of the main criticisms of GANs from an artistic perspective—I’m thinking of Mario Carpo in Artforum—is that GANs can only mimic.
In the art world, mimicry is basically a four-letter word; it’s considered pre-modern, archaic. Is that an accurate understanding of what the technologies can do?

Ian Goodfellow: I did a talk at the NIPS 2017 Workshop on Creativity and Design, where that was essentially my thesis. I tried to be a little bit humble and stay in my lane; I don't have any art credentials or any philosophy credentials. But if I look at the dictionary definitions of words like "creativity" and "imagination," those words are subtly different.
I would say imagination just means being able to conjure up a sensory experience in your mind that isn't driven by your senses. So can GANs create an image that isn't actually there, being driven by camera sensors? Yeah, certainly. That's what they're designed to do.
Creativity seems to require more novelty than what is there in GANs.
GANs are, by design, meant to go for a very specific novelty where they're told, “We want you to draw a new sample from the same distribution but we very intentionally don't want you to try to invent things that wouldn't be in that distribution.” So you explicitly don't want it to be Picasso; Picasso is out of distribution. That's more creative than the specification for GANs.
I'd say that GANs have imagination but not creativity.
Then there are a lot of interesting questions about whether you have to use GANs in the way that they're described in the training process, where all you do is you train them and then you draw samples from the distribution from them. We've seen people take their decoder and use it to make paintbrushes.
Then they can become really interesting tools for creativity, where the human is the creative one and the GAN provides a function that's really different from just drawing samples from the distribution. But it's still not the GAN that's really being creative.
The part that's philosophically different is when you mess around with materials and the materials give you an interesting effect. Are you calling the materials creative? I'd say the same thing is happening with GANs. When you get an interesting paintbrush out of a GAN, I don't feel like the algorithm had intentionality there. It's more like you train this thing and it turns out that if you crack its brain open, you find an interesting paintbrush in there.
But the learning algorithm wasn't trying to make an interesting paintbrush.
Peter Bauman: So when you said that they can do more than mimic at the end of that 2017 talk, you meant, “when humans intervene”? But on their own, what they fundamentally do is mimicry.
Ian Goodfellow: Yeah. When you start poking around inside and say, “Oh, I found this really cool brush,” that's the human being creative.
Peter Bauman: Carpo at the beginning of 2025 seems to clarify his point to basically what you said: that you can separate the human creativity and the machine creativity. You’d agree?

Ian Goodfellow: I think what gets more interesting is when you get to the era of text-prompt-driven conditional models, which GANs didn't really participate in that much. There is, for example, GigaGAN, where these large GANs have been trying to go from text to images.
In the generative model framing, those are still basically just outputting an image from the probability distribution of images conditioned on that text. But we're also seeing that those models do get trained with reinforcement learning and human feedback. For example, Midjourney asks users to rate images. You can actually earn more time on the server by rating images.
So at that point, what I'm saying about this all being purely probability is no longer true: it's also probability and a reward estimate.
Then the question of how much creativity is involved does start to get a little bit harder because at that point the model is placing bets about what a human will like.
Do you get subjective enough that there's an interesting philosophical debate to be had there? That's not what we saw GANs doing a lot of the time. There's a lot of stuff that's more about philosophy and art.
What I can tell you is, “Here are two pieces of tech.” One is definitely not creative. One I'm like, “Oh, let's call a philosopher.”
The one that's definitely not creative—it could be a GAN or any generative model—and you say, “Here's a bunch of faces; train it with a purely probabilistic criterion to make more faces from the same distribution.” I'd say that's imagination but not creativity.
Now, the next piece of tech is we say, "Let's have a person describe what face they wanted to make." Then have a person rate how artistically appealing they found the face that it made and train it with reinforcement learning as well as the generative criterion.
At that point, I'm now thinking this is pretty similar to how a human artist learns from an art teacher.
And it's actually hard for me to argue, just on the basis of what the neural net is doing, that it's not creative. I don't tend to anthropomorphize neural nets a whole lot but I do like to try to say, "What are the actual processes that we do and machines do?"
If the neural net is able to generate something that is not the same as what it was in its training distribution, and there's something that people appreciate about it, that is starting to look to me a lot like it fits my conception of human creativity.
Peter Bauman: A couple of artists that are pertinent here are Lawrence Lek and Mario Klingemann. Klingemann’s BOTTO is similar to what I believe you were describing, where the machine creates images and, based on human reinforcement, can alter them. I would consider that partially autonomous.
Then Lawrence Lek talks about fully autonomous artists having the agency to choose to be an artist. Lek describes a smart satellite that decides to stop surveilling Earth and just make art on its own.
Ian Goodfellow: I find having some creativity in what you do as quite a lower bar than being a fully autonomous artist. I see a pretty big gap between those two things.
Artists have some goals about what they want to communicate to other people about their own life. AI agents just don't have that independent existence.
I don't feel like there's enough AI personhood for them to even have the possibility of being an autonomous artist right now.
Peter Bauman: I also want to get your opinion on how impactful you think these technologies will continue to be moving forward. There’s a debate about whether this is all a bubble and will be gone in a few years or whether generative AI is on par with a new internet and the next step to AGI. Where do you stand at or between those poles?
Ian Goodfellow: I think it will keep going. There have been waves of more and more people paying attention to neural nets. Neural nets were essentially dead for most of the '90s. Andrew Ng is known as a big deep learning guy now.
But when I first took his class as an undergrad, the Intro to AI class, I went up to him at the end of it and I said, "Well, wait a minute, why were there no neural nets in the class?"
He said, “Oh, they don't work. Don't bother learning about them.” And it was actually pretty much exactly that month that Geoffrey Hinton presented Deep Belief Networks at NIPS 2006. They got a new state of the art on MNIST, beating Support Vector Machines, which were the big academic thing at the time.
Everybody has their moment where they feel like, “This is what put deep learning on the map.” And for most of the world today, I think that's ChatGPT. But for me, it's Deep Belief Networks beating Support Vector Machines.
Everybody is like, “These things are slowing down because ChatGPT 5 was a disappointment.” But that's such a small speed bump compared to where things have been going.
Look at the time scale from the '90s. If you zoom out that far, it’s like looking at the stock market zoomed out since the '90s. Then you don’t freak out about a little day-to-day oscillation. I think that these technologies are going to continue growing in capability and importance.
Peter Bauman: What's so interesting about GANs is that they have this direct part in the story of what a lot of people think, too, is what put deep generative models on the map, which is text-to-image. GANs were a significant part of their development. Artists Ryan Murdock and Katherine Crowson started combining GANs with other technologies like CLIP to create the very first openly available text-to-image models. So they were very artist-driven.
Ian Goodfellow: The generative model story and how it turned into media, I think, is a pretty useful one to tell…
For the second half of the conversation, watch it on our YouTube channel (audio only) or as a podcast.
-----
Ian Goodfellow has been a deep learning researcher since about 2008. He invented GANs and is the lead author of the MIT Press textbook Deep Learning. He developed the first defenses against adversarial examples, was among the first to study the security and privacy of neural networks, and helped to popularize the field of machine learning security and privacy. Previously, Ian worked at OpenAI and Willow Garage. He studied with Andrew Ng and Gary Bradski at Stanford University and with Yoshua Bengio and Aaron Courville at Université de Montréal.
Peter Bauman (Monk Antony) is Le Random's editor in chief.